
An illustration that shows a family sitting together at a table exchanging gifts., We’re making it easier to find Mother’s Day gifts with a new shopping experience.
We’re making it easier to find Mother’s Day gifts with a new shopping experience.
Category Archives: Uncategorized
How brands can get the most out of YouTube Shorts adsHow brands can get the most out of YouTube Shorts ads
We are introducing more ways and creative guidance for brands to reach audiences on YouTube Shorts.
Enhance visual storytelling in Demand Gen with generative AIEnhance visual storytelling in Demand Gen with generative AI
An image that shows how generative assets may look across Google and YouTube’s immersive surfaces.,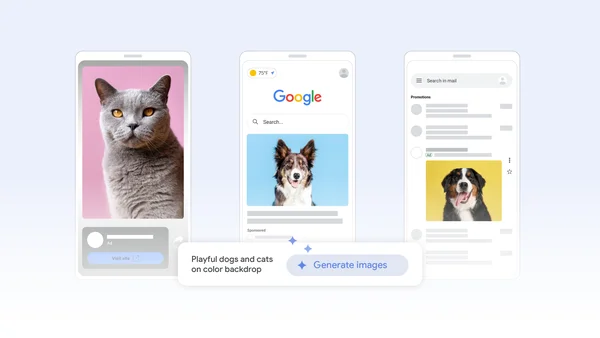 New generative image tools are coming to Demand Gen to help you create a variety of high-quality, stunning image assets with ease.
New generative image tools are coming to Demand Gen to help you create a variety of high-quality, stunning image assets with ease.
6 ways to travel smarter this summer using Google tools6 ways to travel smarter this summer using Google tools
Illustration showing photos of a t-shirt, mountains and a beach, We’re sharing a few helpful tools from Search, Maps and Shopping ahead of the summer travel season.
We’re sharing a few helpful tools from Search, Maps and Shopping ahead of the summer travel season.
Get more personalized shopping options with these Google toolsGet more personalized shopping options with these Google tools
An illustration shows a person sitting with a mobile phone. The background shows “thumbs up” and “thumbs down” images, plus large abstract mobile phones with clothing and shoes., We’re making it easier for shoppers to find what they want through personalized shopping tools.
We’re making it easier for shoppers to find what they want through personalized shopping tools.
Our 2023 Ads Safety ReportOur 2023 Ads Safety Report
A blue shield featuring a white “G” with a grey background, Google’s annual Ads Safety Report details Google’s efforts to prevent malicious use of our ads platforms.
Google’s annual Ads Safety Report details Google’s efforts to prevent malicious use of our ads platforms.
Our 2023 Ads Safety ReportOur 2023 Ads Safety Report
A blue shield featuring a white “G” with a grey background,Google’s annual Ads Safety Report details Google’s efforts to prevent malicious use of our ads platforms.
Evolving Google Analytics for more insightful measurementEvolving Google Analytics for more insightful measurement
Image of a computer screen with five icons representing a line chart with a dollar sign, a pie chart, an ad for a mug, a bar chart and a blue shield., New tools in Google Ads and Analytics allow you to simplify your measurement and are more seamless to adopt.
New tools in Google Ads and Analytics allow you to simplify your measurement and are more seamless to adopt.
Power the next wave of games growth with ads innovationPower the next wave of games growth with ads innovation
Game panel featuring player ranking with “Google for Games 2024 Developer Summit” text on the left, New product announcements from Google Ads and AdMob at the 2024 Google for Games Developer Summit for mobile game developers.
New product announcements from Google Ads and AdMob at the 2024 Google for Games Developer Summit for mobile game developers.
Empowering your team to build best-in-class MMMsEmpowering your team to build best-in-class MMMs
Visual of a 3 line graph transforming into a pie chart and surrounded by additional data visuals., Introducing Meridian, Google’s first open source MMM.
Introducing Meridian, Google’s first open source MMM.
